



版本:Python3.10
模块:requests、urllib等
先说说动态加载图片吧。即指html刚加载时,图片是没有的,而后经过json发生有关图片的数据,在插入到html里面去,以到底快速打开网页的目的,那么问题来了?咱们如何找到加载文件的json文件呢?而这个问题正是咱们实现爬取百度图片的第一步。
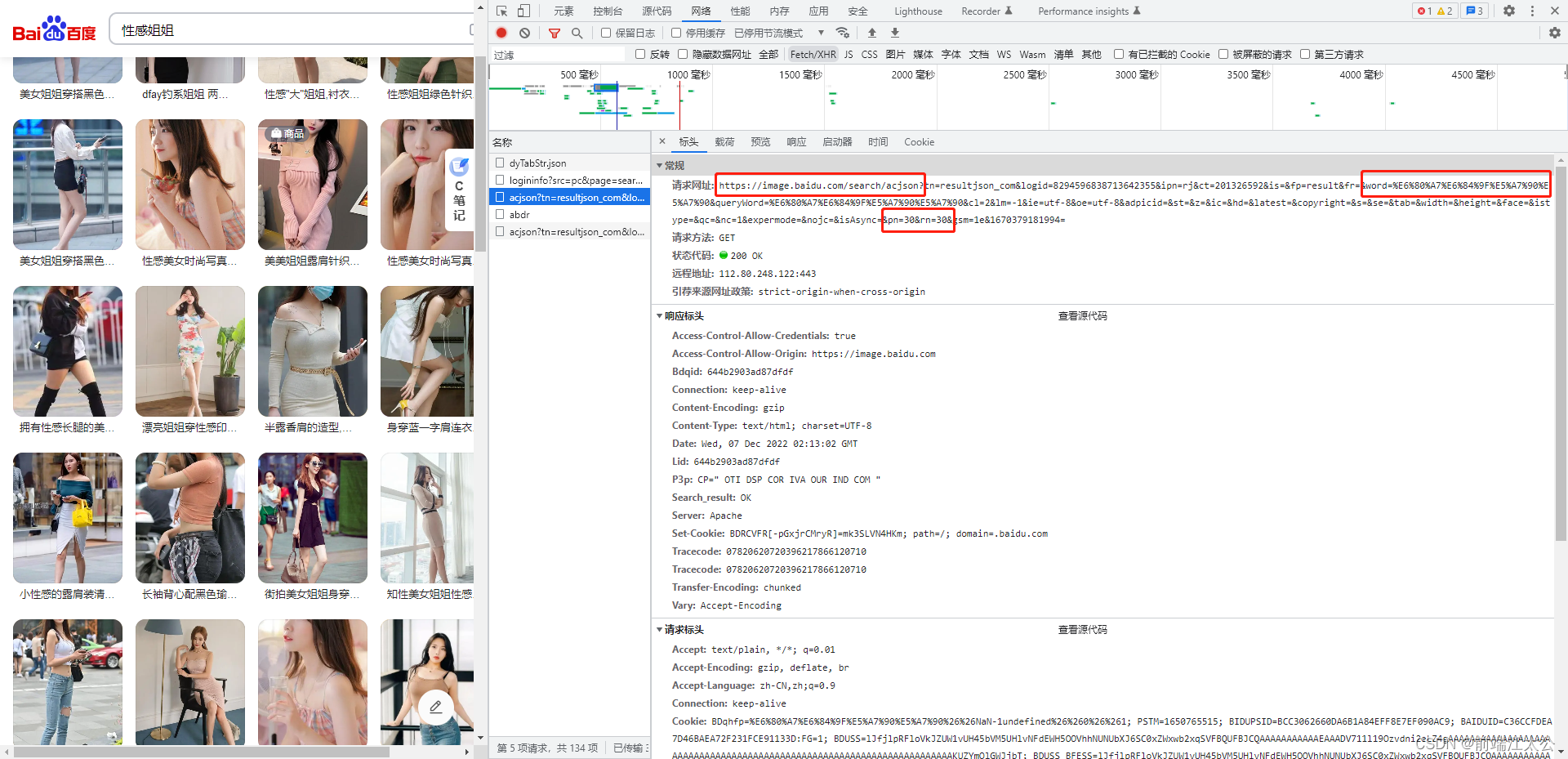
看 json url :
https://image.baidu.com/search/acjson?tn=resultjson_com&logid=7995454107185675365&ipn=rj&ct=201326592&is=&fp=result&fr=&word=%E6%80%A7%E6%84%9F%E5%A7%90%E5%A7%90&queryWord=%E6%80%A7%E6%84%9F%E5%A7%90%E5%A7%90&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&expermode=&nojc=&isAsync=&pn=30&rn=30&gsm=1e&1670379012819=
参数解析:
word:%E6%80%A7%E6%84%9F%E5%A7%90%E5%A7%90
queryWord:%E6%80%A7%E6%84%9F%E5%A7%90%E5%A7%90
这两个参数一样的,应该没什么区别,都是搜索关键词的意思。后面的值就是UrlEncode编码了。
pn是从第几张图片获取 百度图片下滑时默认一次性显示30张。
标红处为关键字word的编码格式,能够用urllib.parse.unquote()解码,第二个为每次涮新的步长,计算为rm+上一个pnui
这里你只要记住咱们要找的图片连接为objURL就行,能够经过re模块compile与find_all方法找出这个json文件的全部objurl,有了这些objurl,到了这里咱们就离成功爬取百度图片不远了。ps因为百度图片的objurl加密了,因此解密过程就不解释了。
话不多说,直接上百度图片爬虫源代码:
import json
import itertools
import urllib
import requests
import os
import re
import sys
word = input("请输入图片关键字:")
path = "./image" #存储路径
if not os.path.exists(path):
os.mkdir(path)
word = urllib.parse.quote(word)
print('正在抓取图片...')
url = r"http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&fp=result&queryWord={word}&cl=2&lm=-1&ie=utf-8&oe=utf-8&st=-1&ic=0&word={word}&face=0&istype=2nc=1&pn={pn}&rn=60"
urls = (url.format(word=word, pn=x) for x in itertools.count(start=0, step=60))
index = 0
str_table = {
'_z2C$q': ':',
'_z&e3B': '.',
'AzdH3F': '/'
}
print('请求中...')
char_table = {
'w': 'a',
'k': 'b',
'v': 'c',
'1': 'd',
'j': 'e',
'u': 'f',
'2': 'g',
'i': 'h',
't': 'i',
'3': 'j',
'h': 'k',
's': 'l',
'4': 'm',
'g': 'n',
'5': 'o',
'r': 'p',
'q': 'q',
'6': 'r',
'f': 's',
'p': 't',
'7': 'u',
'e': 'v',
'o': 'w',
'8': '1',
'd': '2',
'n': '3',
'9': '4',
'c': '5',
'm': '6',
'0': '7',
'b': '8',
'l': '9',
'a': '0'
}
i = 0
char_table = {ord(key): ord(value) for key, value in char_table.items()}
print('准备开始,请稍后...')
for url in urls:
html = requests.get(url, timeout=10).text
a = re.compile(r'"objURL":"(.*?)"')
downURL = re.findall(a, html)
for t in downURL:
for key, value in str_table.items():
t = t.replace(key, value)
t = t.translate(char_table)
try:
html_1 = requests.get(t)
if str(html_1.status_code)[0] == "4":
print('失败1')
continue
except Exception as e:
print('失败2')
continue
with open(path + "/" +'img_'+ str(i) + ".png", 'wb') as f:
f.write(html_1.content)
i = i + 1
print('正在爬取第 '+str(i)+' 张图片...')
直接运行
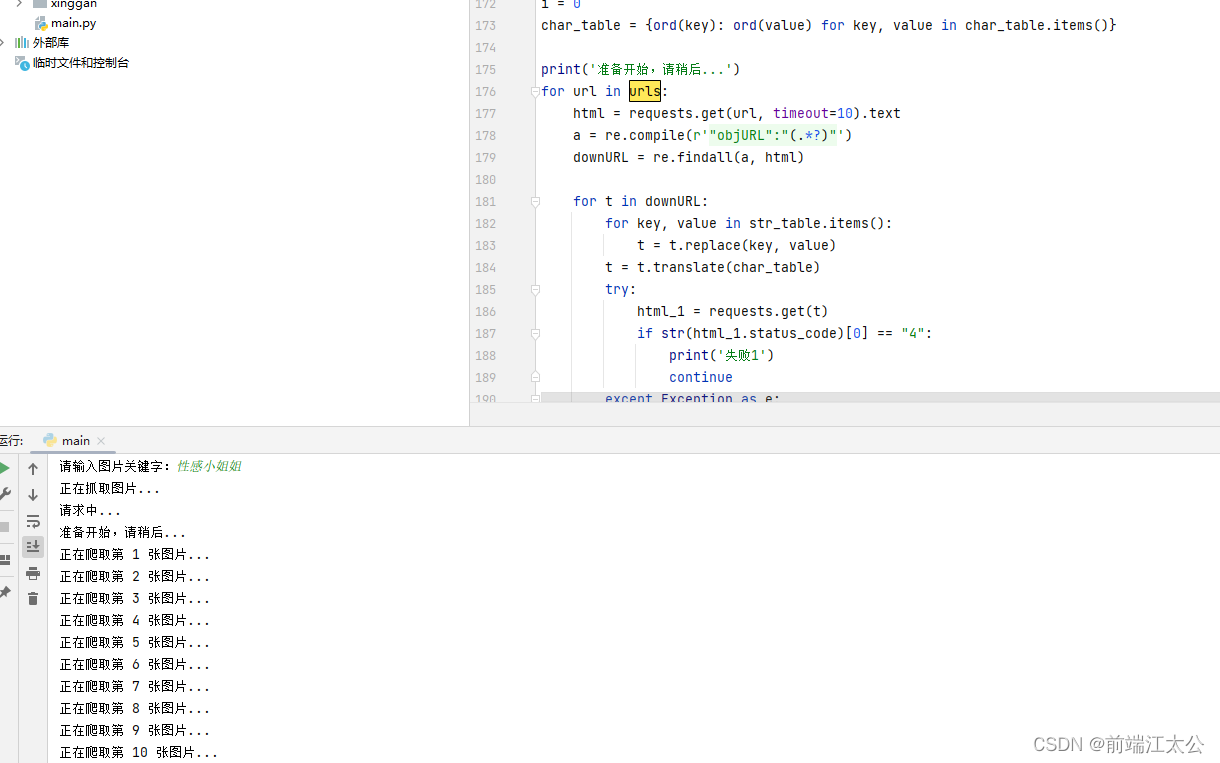

后面在附两个不太友好的源码。容易出错或者爬的很慢,你们可以去做优化。
1、爬的慢
import time
import requests
import urllib
page = input("请输入要爬取多少页:")
page = int(page) + 1 # 确保其至少是一页,因为 输入值可以是 0
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
n = 0 # 图片的前缀 如 0.png
pn = 1 # pn是从第几张图片获取 百度图片下滑时默认一次性显示30张
storage="D:\Python_demo\crawler_image\image" # 本地存储地址
img_name="\清纯小姐姐_" #图片命名
for m in range(1, page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': '8846269338939606587',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': '清纯',
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': '清纯',
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': pn,
'rn': '30',
'gsm': '1e',
}
page_info = requests.get(url=url, headers=header, params=param)
page_info.encoding = 'utf-8' # 确保解析的格式是utf-8的
page_info = page_info.json() # 转化为json格式在后面可以遍历字典获取其值
info_list = page_info['data'] # 观察发现data中存在 需要用到的url地址
del info_list[-1] # 每一页的图片30张,下标是从 0 开始 29结束 ,那么请求的数据要删除第30个即 29为下标结束点
img_path_list = []
for i in info_list:
img_path_list.append(i['thumbURL'])
n = n + 1
print('第 ' + str(n) + ' 张图片')
for index in range(len(img_path_list)):
# print('图片url地址:'+img_path_list[index]) # 所有的图片的访问地址
time.sleep(0.0001)
# urllib.request.urlretrieve(img_path_list[index], storage+img_name + str(n) + '.jpg')
image = requests.get(img_path_list[index]).content
imagenname='图片' +str(n)+ '.png'
with open('./image/%s' % imagenname.split("&")[0], 'wb') as file:
file.write(image)
pn += 29
2、易出错
import requests
import re
# 确定网址
url = 'https://image.baidu.com/search/index?ct=201326592&z=&tn=baiduimage&ipn=r&word=%E6%B8%85%E7%BA%AF'
form_header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.190 Safari/537.36",
"Host": "image.baidu.com",
"Accept-Language": "zh-CN,zh;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"
}
res = requests.get(url, headers=form_header).text
print(res)
image_urls = re.findall('"objURL":"(.*?)",', res)
# print(image_urls)
n = 0 # 图片的前缀 如 0.png
for image_url in image_urls:
print('图片url地址:'+image_url)
# 图片名称
n = n + 1
image_name=str(n)
print('第 '+image_name+' 张图片')
image_end = re.search('(.jpg/.png/.jpeg/.gif/.webp/.bmp)$', image_name)
if image_end == None:
image_name = '清纯壁纸_'+image_name+ '.png'
# 保存
image = requests.get(image_url).content
with open('./image/%s' % image_name.split("&")[0], 'wb') as file:
file.write(image)
下面两个分别是小可爱本身原创编写的爬取蜂鸟网和汇图网的爬虫代码
汇图网爬虫:
import re
import requests
import os
import urllib
header= {'content-type': 'application/json',
'User-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:22.0) Gecko/20100101 Firefox/22.0'}
url="http://soso.huitu.com/Search/GetAllPicInfo?perPageSize=102&kw={word}&page={num}"
word=input("请输入关键字:")
word=urllib.parse.quote(word)
urls=[str(url).format(word=word,num=x)for x in range(1,2)]
i=1
for url in urls:
print(url)
html=requests.get(url).text
print(html)
r=re.compile(r'"imgUrl":"(.*?)"')
u=re.findall(r,html)
for s in u:
htmls=requests.get(s)
with open("F:\\im\\"+str(i)+".jpg",'wb')as f:
f.write(htmls.content)
i=i+1
蜂鸟网爬虫:
import re
import requests
import os
import itertools
url="http://photo.fengniao.com/ajaxPhoto.php?action=getPhotoLists&fid=595&sort=0&page={num}"
i=1
path="F:\\fengniao"
if not os.path.exists(path):
os.mkdir(path)
urls = [url.format(num=x) for x in range(1,100)]
for url in urls:
html = requests.get(url).text
r=re.compile(r'"image":"(.*?)"')
u=re.findall(r, html)
for downurl in u:
downurl=str(downurl).replace("\\","").split("?")[0]
htmls=requests.get(downurl)
with open(path+"\\"+str(i)+".jpg",'wb') as f:
f.write(htmls.content)
i=i+1
print(downurl)
评论区